
Разработчики явно будут довольны
Anthropic представила Claude Opus 4.5 — обновление своей главной ИИ-модели. Упор в ней был вновь сделан на навыки в разработке и работу агентов.
Компания утверждает, что это ее самый сильный релиз и фактически «лучшая модель для программирования» на сегодняшний день. Новинка уже доступна в Claude-приложениях, API и на всех крупных облаках: AWS, Azure и Google Cloud.
Anthropic подчеркивает: модель стала умнее не только в том, что выдает, но и как именно она думает. Меньше повторов, меньше блужданий и меньше бесполезной траты токенов.
Рекордные результаты
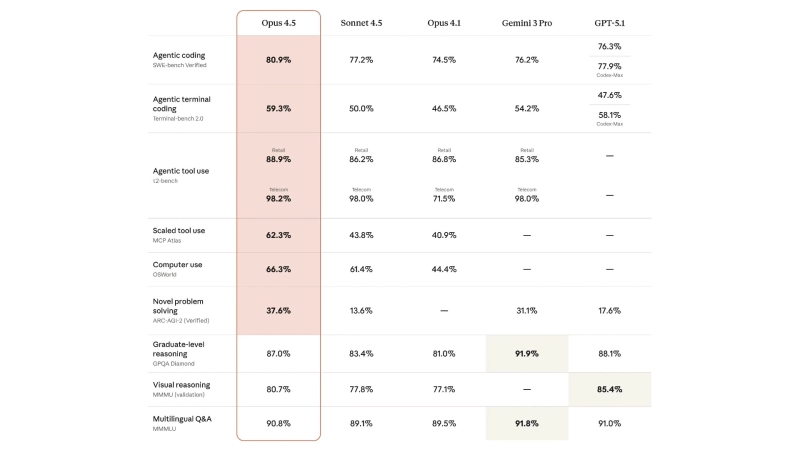
Главный маркетинговый тезис разработчиков Opus 4.5 заключается в том, что их модели удалось набрать 80,9% в тестах SWE-Bench Verified. Это официальный рекорд, который чуть обогнал результаты последних Gemini 3 и GPT-5.1-Codex-Max.
Кроме того, Opus 4.5 прошел внутренний двухчасовой инженерный экзамен Anthropic и показал себя лучше любого человека, участвовавшего в тесте.
Но для нас, как пользователей, важнее другое: модель стала существенно экономичнее. По заявлениям Anthropic, она тратит до 60–70% меньше токенов, чем прошлые версии, чтобы прийти к тому же ответу.
Так, например, в reasoning-режиме Opus 4.5 обгоняет Sonnet 4.5 по точности, но использует почти вдвое меньше выходных токенов. При текущем снижении цен ($5 за миллион входных токенов и $25 за миллион выходных) для многих команд это означает реальную экономию в проде.
Улучшения для кодеров: от генерации до планирования
Еще одной важной особенностью модели авторы назвали «инженерные сценарии». Opus 4.5 стал лучше в нескольких практических задачах:
- разбор больших кодовых баз,
- написание и правка модулей,
- генерация тестов,
- поиск ошибок и переписывание сложных кусков,
- работа в агентном режиме с инструментами.
Отдельно улучшили Claude Code: теперь модель сначала задает уточняющие вопросы, затем строит план, создает editable plan.md и только после этого начинает выполнять шаги.
В Anthropic заявили, что это напоминает поведение «очень методичного миддла».